This post compares several discrimination characteristic extraction models, with more details in my Github repository.
Why Feature Extraction Matters
Feature extraction is a key step in machine learning that transforms raw data into a set of useful, non-redundant features. This process:
- Improves the performance of learning algorithms
- Enhances generalization
- Makes the data easier for humans to understand
In this study, we apply various visualization and data reduction methods to the Fashion-MNIST dataset and integrate them with a specific learning model.
Understanding Autoencoders
Autoencoders have a long history in machine learning:
- First mentioned in a 1986 paper on backpropagation
- A 1989 article highlighted their ability to extract linear features
- Later research showed they could also find non-linear factorial representations
We were inspired to compare Principal Component Analysis (PCA) and autoencoders on a complex dataset after a mini-project. Visualizing the results using clustering helped us understand the effects of encoding.
Key Findings and Future Work
Through this project, we learned a lot about visualization and clustering techniques and the unique properties of autoencoders and their variants.
Key Takeaways:
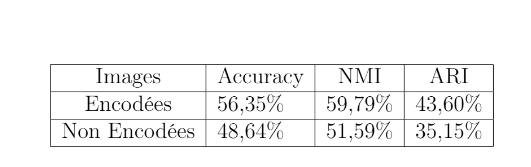
- Autoencoders can greatly improve clustering results, especially when the classes in a dataset are unknown
- The t-SNE method is useful for visualizing data distribution
- The Kullback-Leibler divergence and its link to mutual information helped evaluate our results
Potential Next Steps:
- Build a variational autoencoder architecture with convolutional layers
- Experiment with different K-means parameters to optimize accuracy
Overall, this exploration allowed us to effectively visualize and classify the Fashion-MNIST dataset, which is more complex than the standard MNIST dataset.