In artificial intelligence (AI) and machine learning, double descent is an interesting phenomenon where a model’s prediction error first decreases, then increases, and finally decreases again as model complexity increases. This goes against the traditional U-shaped bias-variance trade-off curve that has been the foundation of machine learning theory.
Tian-Le Yang and Joe Suzuki from Osaka University’s Graduate School of Engineering Science recently published a research paper titled “Dropout Drops Double Descent”. They introduce a new way to reduce double descent using dropout, a popular regularization technique. This article analyzes their research, explaining the complex concepts in a clear and understandable way.
What are Dropout and Double Descent?
Double descent is when a model’s prediction error:
- Decreases at first
- Then increases
- Finally decreases again
as the model becomes more complex. This is different from the traditional U-shaped curve that shows the trade-off between bias and variance.
Dropout is a regularization technique used when training deep neural networks. It randomly “drops” neurons during training to prevent overfitting. This helps the model generalize better from the training data to new, unseen data.
The main question the paper tries to answer is: “When and How can dropout drop the double descent?” The researchers look at this in both linear and nonlinear models to improve test performance without unexpected non-monotonic responses.
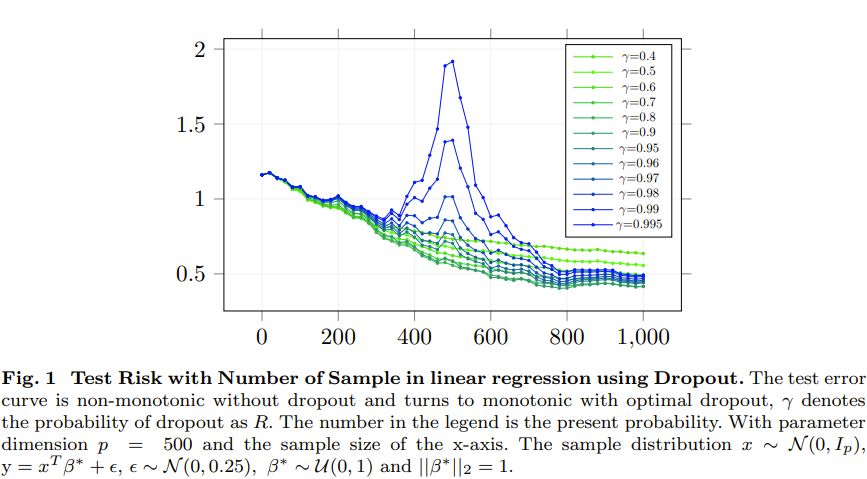
Analyzing the Theory and Experiments
The paper provides both theoretical analysis and experiments to answer the main question. For the theory, the authors study linear regression with dropout regularization. They show it has a similar effect as general ridge regression. They prove that dropout regularization can reduce double descent in isotropic regression.
For the experiments, the authors show that dropout can avoid double descent in both linear and nonlinear models. They prove that test error decreases as sample size increases when using the best dropout rate. They also show that test error decreases as model size increases when using the best dropout rate.
Main Contributions
The key contributions of the paper are:
- Theoretically and experimentally proving that test error decreases as sample size increases with the optimal dropout rate.
- Theoretically and experimentally proving that test error decreases as model size increases with the optimal dropout rate.
- Theoretically proving that test error decreases in nonlinear random feature regression with dropout, and experimentally showing this in nonlinear models.
The Takeaway
The paper concludes that it’s important to consider dropout for risk curve scaling when seeing the peak in the double descent curve. The findings suggest that dropout can be a powerful tool for reducing double descent and improving machine learning model performance.
This research gives new ideas for further exploring how dropout and double descent are related. It also provides useful insights for machine learning practitioners. By understanding these concepts, we can design AI models that are more robust, efficient, and better able to handle real-world challenges.
Questions to Think About
- How can we use the findings of this research to make existing machine learning models work better?
- What could this research mean for the larger field of AI and machine learning, especially in terms of model complexity and overfitting?
- How could future research build on these findings to further explore the relationship between dropout and double descent?
- Could dropout be combined with other regularization methods to improve machine learning model performance even more?
- How could the idea of double descent be used in other areas of machine learning and AI, beyond what this research covers?
In summary, “Dropout Drops Double Descent” by Tian-Le Yang and Joe Suzuki is an important contribution to machine learning. It provides a better understanding of the double descent phenomenon and how dropout can help reduce it. The research offers both theoretical insights and practical guidance for AI practitioners looking to optimize their models. As we continue to advance AI and machine learning, research like this is extremely valuable in guiding our understanding and application of these complex systems.
Stay tuned for more updates and in-depth analyses of the latest AI and machine learning research. If you have any questions or want to discuss this topic more, please leave a comment below.