Finetuning is an important process for improving the performance of large language models (LLMs) and customizing their behavior for specific tasks. However, finetuning very large models can be extremely expensive due to the large amounts of memory needed. Researchers from the University of Washington have developed a new solution called QLORA (Quantized Low Rank Adapters) to address this challenge.
What is QLORA?
QLORA is an efficient approach to finetuning that significantly reduces memory usage. It allows finetuning a 65 billion parameter model on a single 48GB GPU while maintaining the same performance as full 16-bit finetuning.
The key steps in QLORA are:
- Use a frozen, 4-bit quantized pretrained language model
- Backpropagate gradients into Low Rank Adapters (LoRA)
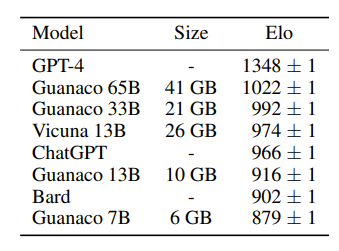
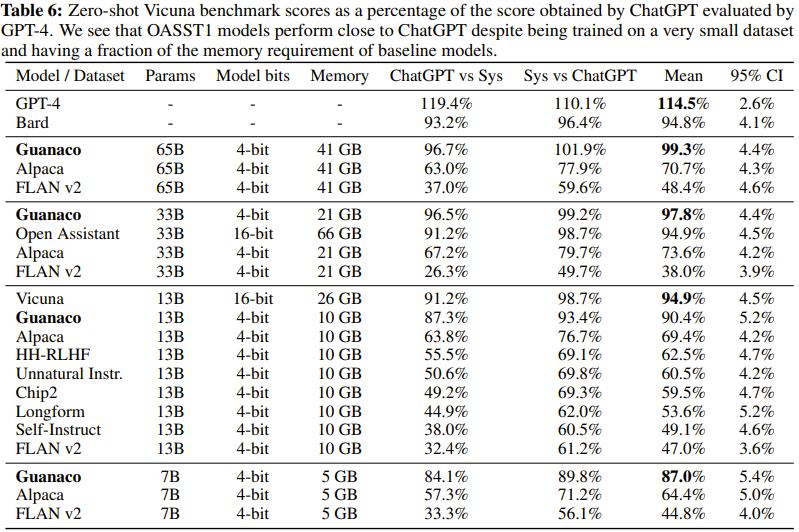
The researchers also created a new model family called Guanaco. Guanaco models outperform all previous openly released models on the Vicuna benchmark. They reach 99.3% of ChatGPT’s performance while only needing 24 hours of finetuning on a single GPU.
Key Innovations in QLORA
QLORA introduces several new techniques to reduce memory usage without hurting performance:
- 4-bit NormalFloat (NF4): A new data type that is optimal for normally distributed weights
- Double Quantization: Reduces average memory footprint by quantizing the quantization constants
- Paged Optimizers: Manages memory spikes
Analyzing Performance
The researchers did a detailed study of instruction finetuning and chatbot performance on model scales that would be impossible with regular finetuning due to memory needs. They trained over 1,000 models with sizes from 80 million to 65 billion parameters.
Key findings:
- QLORA finetuning on a small high-quality dataset gives state-of-the-art results, even with smaller models
- Data quality matters much more than dataset size
Evaluating Chatbot Performance
The researchers analyzed chatbot performance using both human raters and GPT-4. They used a tournament-style approach where models compete to give the best response to a prompt. The winner of each match is judged by either GPT-4 or humans. The tournament results are turned into Elo scores which rank chatbot performance.
Open Sourcing the Work
The researchers have released all of their models and code, including CUDA kernels for 4-bit training. They integrated their methods into the Hugging Face transformers library to make them easily usable. They released adapters for 7B, 13B, 33B and 65B size models trained on 8 different instruction following datasets, for a total of 32 open-sourced finetuned models.
The Significance of QLORA
QLORA is an important step forward in efficiently finetuning large language models. By greatly reducing memory needs without sacrificing performance, it enables new possibilities for developing and using these powerful models. Releasing the models and code open source will surely drive further innovation in this exciting field.
To learn more about the technical details and full experimental results, please see the QLORA GitHub project and the paper QLORA: Efficient Finetuning of Quantized LLMs.