Introduction to Federated Learning and Its Security Challenges
Federated Learning (FL) has revolutionized machine learning by enabling model training across distributed devices while preserving data privacy. However, this decentralized approach introduces unique security vulnerabilities, particularly label-flipping attacks. In these attacks, malicious actors alter data labels on their local devices, potentially compromising the integrity of the global model.
This post examines an innovative approach to bolster FL security through a streamlined consensus-based verification process combined with an adaptive thresholding mechanism. This method ensures that only validated and agreed-upon modifications are incorporated into the global model, significantly reducing the impact of label-flipping attacks.
The Consensus-Based Label Verification Algorithm: A Detailed Look
The proposed algorithm operates through several key steps:
- Initialization:
- The shared machine learning model is distributed to all participating clients.
- A report for tracking suspicious updates is initialized.
- Client Update Generation:
- Each client trains the model using its local dataset.
- Clients submit their model updates to the central server.
- Consensus-Based Label Verification:
- For each client update:
- The update is applied to a temporary version of the model.
- This temporary model predicts labels for a trusted dataset.
- The algorithm compares these predictions to the true labels.
- A discrepancy measure is calculated to quantify the difference.
- For each client update:
- Model Aggregation:
- Updates that pass the verification process are aggregated to update the global model.
- Suspicious updates are flagged and excluded from the aggregation.
- Adaptive Threshold Adjustment:
- The discrepancy threshold is dynamically adjusted based on:
- The distribution of observed discrepancies
- Current model performance metrics
- The discrepancy threshold is dynamically adjusted based on:
This adaptive approach allows the system to respond to changing patterns in the data and potential attacks, maintaining a balance between security and model improvement.
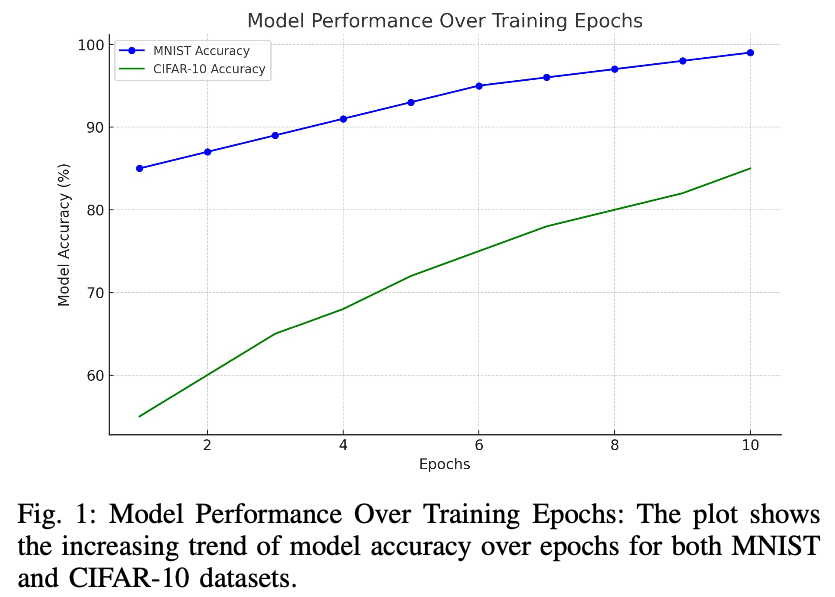
Figure 1 demonstrates how the adaptive threshold mechanism maintains high model accuracy throughout the training process for both MNIST and CIFAR-10 datasets. The graph shows the threshold adjusting over time, allowing the algorithm to adapt to changing data patterns and potential attacks while preserving model performance.
Experimental Results and Analysis
The Consensus-Based Label Verification Algorithm was rigorously tested using two benchmark datasets in machine learning: MNIST and CIFAR-10. These datasets were chosen for their contrasting complexity levels, providing a comprehensive evaluation of the algorithm’s effectiveness.
Performance on MNIST
The algorithm achieved remarkable results on the MNIST dataset:
- Final model accuracy: 99%
- This high accuracy demonstrates the algorithm’s ability to maintain model integrity even in the presence of potential label-flipping attacks.
Performance on CIFAR-10
The CIFAR-10 dataset, known for its greater complexity, showed steady improvement:
- Initial accuracy: 55%
- Final accuracy: 85%
- The consistent increase in accuracy over training epochs highlights the algorithm’s adaptability to more challenging datasets.
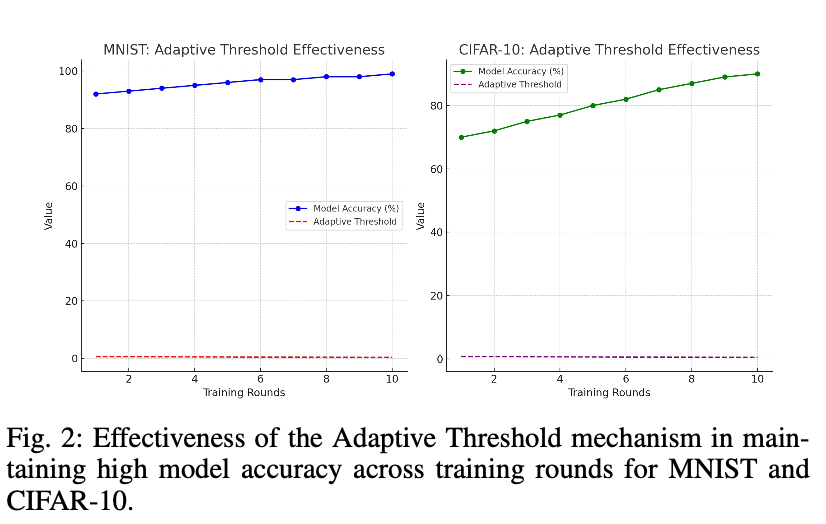
Figure 2 illustrates the progression of model accuracy over training epochs for both MNIST and CIFAR-10 datasets. The graph clearly shows the algorithm’s ability to improve model performance consistently, even when dealing with datasets of varying complexity.
These results validate the robustness of the Consensus-Based Label Verification Algorithm. The dynamic thresholding mechanism plays a crucial role in the model’s ability to distinguish between legitimate and potentially malicious updates, contributing significantly to its overall performance and security.
Comparative Analysis with Existing Methods
To assess the effectiveness of the Consensus-Based Label Verification Algorithm, a comparative study was conducted against two contemporary approaches:
- An anomaly detection-based method (Method A)
- A robust aggregation strategy (Method B)
The comparison was performed using identical operational parameters on both the MNIST and CIFAR-10 datasets. Each dataset was subjected to label-flipping attacks affecting 10% of the data to simulate realistic adversarial conditions.
Key metrics used for evaluation included:
- Model accuracy
- Attack detection rate
- False positive rate (FPR)
- False negative rate (FNR)
The results of this comparative analysis are presented in the following table:
| Metric/Method | Consensus-Based Algorithm | Method A | Method B |
|---|---|---|---|
| MNIST Accuracy | 99.47% | 98.90% | 99.10% |
| CIFAR-10 Accuracy | 92.20% | 90.50% | 91.00% |
| MNIST Attack Detection Rate | 90.26% | 85.00% | 87.50% |
| CIFAR-10 Attack Detection Rate | 85.33% | 82.00% | 83.50% |
| MNIST FPR | 0.00% | 5.00% | 3.00% |
| CIFAR-10 FPR | 2.00% | 7.00% | 5.00% |
| MNIST FNR | 8.74% | 12.00% | 10.00% |
| CIFAR-10 FNR | 10.00% | 15.00% | 12.00% |
Table 1: Comparative analysis of performance metrics across the MNIST and CIFAR-10 datasets.
The Consensus-Based Label Verification Algorithm outperformed both comparative methods across all evaluated metrics:
-
Higher Accuracy: Achieved superior accuracy rates on both MNIST and CIFAR-10, demonstrating its effectiveness in diverse learning environments.
-
Improved Attack Detection: Showed higher detection rates for adversarial activities, indicating its enhanced ability to identify and mitigate potential threats.
-
Lower False Positive Rates: Particularly notable is the 0% false positive rate achieved on MNIST, showcasing the algorithm’s precision in validating genuine updates without mistakenly flagging them as adversarial.
-
Reduced False Negative Rates: Lower false negative rates compared to other methods highlight the algorithm’s improved ability to distinguish between legitimate and adversarial updates.
These results underscore the Consensus-Based Label Verification Algorithm’s effectiveness as a robust defense mechanism for Federated Learning systems, offering enhanced security without compromising on model performance.
Conclusion and Future Directions
The Consensus-Based Label Verification Algorithm represents a significant advancement in securing Federated Learning systems against label-flipping attacks. By combining adaptive thresholding with consensus-based validation, this approach offers:
- Enhanced resilience against adversarial attacks
- Improved model integrity and accuracy in challenging environments
- A scalable and efficient defense mechanism with minimal computational overhead
The algorithm’s superior performance on both MNIST and CIFAR-10 datasets, compared to existing methods, demonstrates its potential for real-world applications across various domains where data privacy and model security are paramount.
Future research directions may include:
- Extending the algorithm’s applicability to other types of adversarial attacks in Federated Learning
- Exploring its performance in more diverse and complex datasets
- Investigating potential optimizations to further reduce computational costs
- Examining the algorithm’s effectiveness in specific industry applications, such as healthcare or finance
This work lays a foundation for more secure and reliable Federated Learning systems, moving closer to realizing the full potential of collaborative, privacy-preserving machine learning in adversarial environments.