Introduction
One-shot federated learning (OFL) is a promising technique that allows the training of a global server model using only a single communication round. In OFL, the server model is created by distilling knowledge from an ensemble of client models. These client models are also responsible for generating synthetic data samples used in the distillation process. The effectiveness of the server model is closely tied to two key factors: the quality of the synthesized data and the performance of the ensemble.
The Co-Boosting Framework
To address the limitations of existing OFL methods, researchers have developed a new approach called Co-Boosting. This framework aims to improve both the synthesized data and the ensemble model simultaneously, leading to better overall performance.
The Co-Boosting process consists of three main steps:
-
Generation of High-Quality Samples: The framework creates challenging samples based on the current ensemble and server models. These samples are designed to be more informative for the learning process.
-
Ensemble Improvement: Using the newly generated samples, Co-Boosting adjusts the importance (weight) of each client model in the ensemble. This results in a more effective combined model.
-
Server Model Update: The server model is then updated by distilling knowledge from both the improved data samples and the refined ensemble.
By repeating these steps, Co-Boosting creates a cycle of continuous improvement for both the data and the ensemble, naturally leading to a better-performing server model.

Figure 1 illustrates the core concept of the Co-Boosting approach. In each training cycle, high-quality samples are first generated based on the previous ensemble and server models. These samples are then used to adjust client weights, creating a better ensemble. Finally, the server model is updated using the improved data and refined ensemble.
Experimental Results
The researchers conducted extensive experiments to evaluate the effectiveness of Co-Boosting across various datasets and settings. The results consistently showed that Co-Boosting outperforms existing methods in one-shot federated learning scenarios.
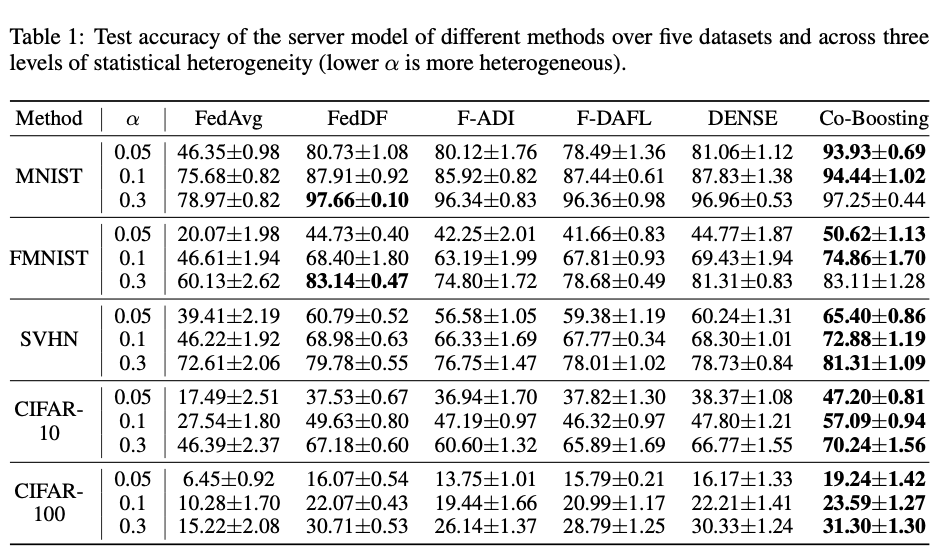
Table 1 presents the test accuracy of server models trained using different methods across five datasets (MNIST, FMNIST, SVHN, CIFAR-10, and CIFAR-100) and three levels of statistical heterogeneity. The results show that Co-Boosting consistently achieves higher accuracy compared to other methods, with significant improvements in scenarios with high data heterogeneity.
Key findings from the experiments include:
-
Performance in Heterogeneous Settings: Co-Boosting showed substantial improvements over baseline methods, especially in scenarios with highly heterogeneous data distributions among clients.
-
Adaptability to Model Heterogeneity: The framework demonstrated its effectiveness even when clients used different model architectures, a common challenge in real-world federated learning scenarios.
-
Robustness to Unbalanced Data: Co-Boosting maintained its performance advantage in settings where clients had varying amounts of local data.
-
Scalability: The method showed consistent improvements as the number of participating clients increased.
Practical Advantages
Co-Boosting offers several practical benefits that make it well-suited for real-world applications:
-
No Client-Side Modifications: Unlike some other methods, Co-Boosting does not require changes to the client’s local training process.
-
Minimal Communication Overhead: The framework does not need additional data or model transmissions beyond the initial client models.
-
Flexibility in Model Architecture: Co-Boosting can work with heterogeneous client model architectures, making it adaptable to diverse federated learning environments.
These characteristics make Co-Boosting particularly valuable in modern model market scenarios, where pre-trained models from various sources may need to be combined effectively.
Conclusion
Co-Boosting represents a significant advancement in one-shot federated learning. By creating a mutually beneficial relationship between data generation and ensemble improvement, this method addresses key challenges in federated learning scenarios. The framework’s ability to generate informative samples and refine the ensemble model leads to improved server model performance without requiring additional client-side adjustments or communication.
The extensive experimental results demonstrate the effectiveness of Co-Boosting across various datasets and challenging scenarios, including data heterogeneity and model diversity. As federated learning continues to gain importance in privacy-preserving machine learning applications, methods like Co-Boosting will play a crucial role in improving the efficiency and effectiveness of these systems.
Future research in this area may focus on further improving the quality of synthetic data generation and exploring ways to make the ensemble weighting process even more effective. Additionally, investigating the application of Co-Boosting to more complex tasks and larger-scale federated learning scenarios could yield valuable insights for the field.