Introduction to Federated Learning and Data Heterogeneity
Federated Learning (FL) is a machine learning approach that allows multiple participants (clients) to train a shared model without exchanging raw data. This method is particularly useful in scenarios where data privacy is crucial, such as healthcare or finance. However, FL faces a significant challenge: data heterogeneity.
Data heterogeneity occurs when the data distributions across clients are not identical. This situation is common in real-world applications, where each client may have unique data characteristics. Traditional FL methods struggle with this issue, often resulting in reduced model performance and slower convergence.
The Limitations of Traditional Federated Learning
Most FL algorithms use an “aggregate-then-adapt” framework:
- Clients update a global model using their local data
- The server aggregates these updates to create a new global model
- The process repeats for multiple rounds
This approach can lead to “client drift,” where local models diverge significantly from the global model, especially when data heterogeneity is high. As a result, the global model’s performance suffers, and the learning process becomes less efficient.
Introducing FedAF: A New Approach to Federated Learning
Researchers have developed FedAF (Federated Learning with Aggregation-Free), a novel algorithm designed to address the challenges of data heterogeneity. FedAF takes a fundamentally different approach:
- Clients create condensed versions of their local data
- The server uses these condensed datasets to train the global model directly
This method avoids the pitfalls of traditional aggregation, leading to improved performance and faster convergence.
Key Techniques in FedAF
FedAF employs two primary techniques to enhance federated learning:
1. Collaborative Data Condensation (CDC)
In CDC, clients create compact representations of their local data while considering information from other clients. This process involves:
- Minimizing a distribution matching loss to ensure the condensed data reflects the original data distribution
- Using a Sliced Wasserstein Distance-based regularization term to align the local knowledge with the broader distribution across clients
This collaborative approach allows clients to create higher-quality condensed data that captures more comprehensive information.
2. Local-Global Knowledge Matching (LGKM)
LGKM enhances the server’s training process by utilizing:
- Condensed data shared by clients
- Soft labels extracted from client data
This combination provides the server with richer information about the original data distributions, leading to a more robust and accurate global model.
FedAF in Action: Workflow Overview
Figure 1 illustrates the key differences between traditional FL and FedAF:
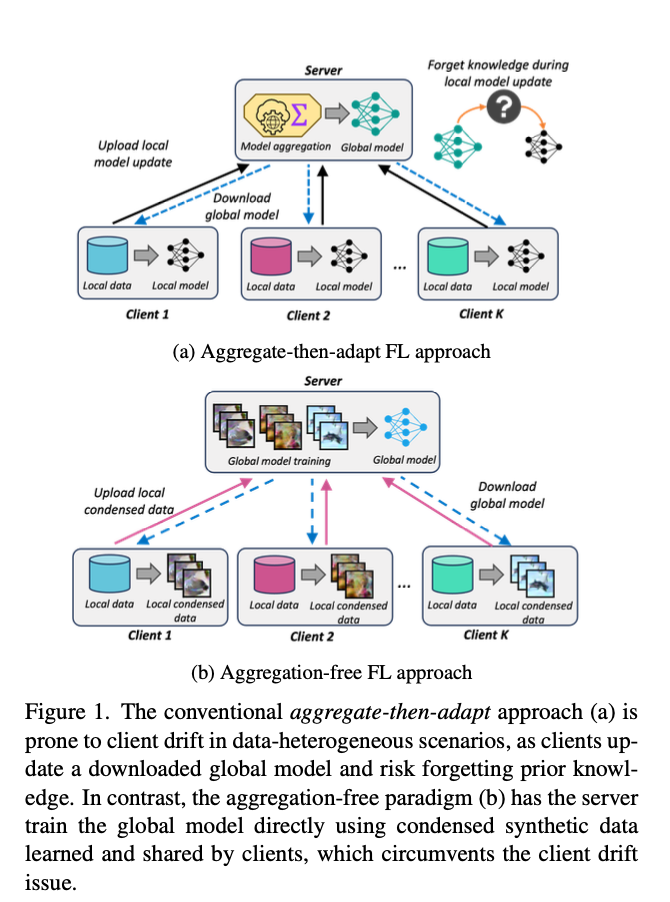
(a) Traditional FL: Clients update a downloaded global model, risking forgetting previous knowledge. (b) FedAF: The server trains the global model using condensed data from clients, avoiding client drift.
Figure 2 provides a detailed overview of the FedAF workflow:
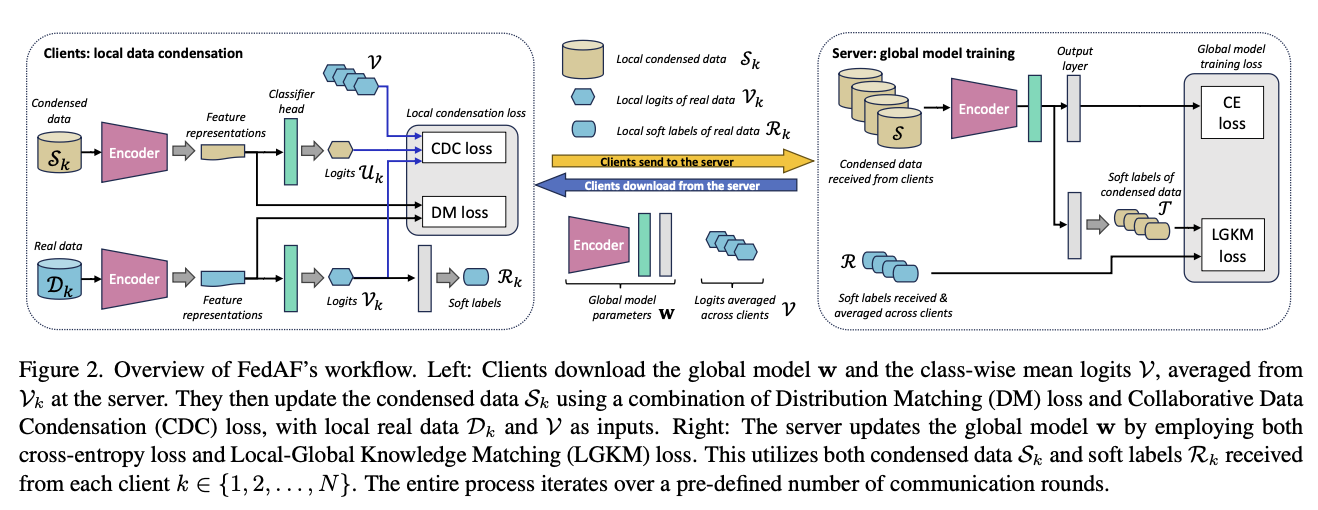
- Clients download the global model and class-wise mean logits
- Clients update their condensed data using CDC
- Clients share condensed data and soft labels with the server
- The server updates the global model using LGKM
This process repeats for multiple communication rounds, continuously improving the global model.
Experimental Results: FedAF’s Performance
Researchers tested FedAF on popular benchmark datasets, including CIFAR10, CIFAR100, and FMNIST. The results show significant improvements over state-of-the-art FL algorithms:
- Accuracy: Up to 25.44% improvement compared to FedAvg on CIFAR10
- Convergence Speed: 80% faster than FedDM on CIFAR10
FedAF consistently outperformed other methods across various degrees of data heterogeneity, demonstrating its effectiveness in handling both label-skew and feature-skew scenarios.
The Impact of FedAF on Federated Learning
FedAF represents a significant advancement in federated learning for heterogeneous data environments. Its key contributions include:
- Eliminating the need for model aggregation, reducing the risk of client drift
- Improving the quality of condensed data through collaborative learning
- Enhancing global model training with richer client information
These improvements lead to more accurate models and faster convergence, making federated learning more practical for real-world applications with diverse data distributions.
Conclusion and Future Directions
FedAF introduces an effective solution to the challenges of data heterogeneity in federated learning. By employing collaborative data condensation and local-global knowledge matching, it achieves superior performance compared to traditional methods.
As federated learning continues to evolve, FedAF opens new avenues for research and practical applications. Future work may focus on:
- Optimizing the data condensation process for different types of data
- Exploring the privacy implications of sharing condensed data
- Adapting FedAF for specific domains such as healthcare or finance
FedAF represents a significant step forward in making federated learning more robust and efficient, paving the way for its wider adoption in privacy-sensitive and data-diverse environments.